[데이터분석](Project 3) 자동차 리콜 데이터 분석 1
자동차 리콜 데이터 분석하기
프로젝트를 통해 EDA(탐색적 데이터 분석) 과정을 연습해보며 리콜 차량의 특징을 알아봅시다.
프로젝트 개요
리콜(recall)은 제품의 설계, 제조 단계에서 결함이 발견되었을 시 문제 예방의 차원에서 판매자가 무상으로 수리, 점검 및 교환을 해주는 소비자 보호 제도입니다. 집집마다 개인용 자동차를 보유하게 되면서 자동차는 어느덧 우리 삶의 일상재가 되었지만, 안전성에 대해서는 산발적인 문제 제기가 계속되고 있고, 이에 따라 전격적인 자동차 리콜 사태도 종종 발생하여 화제를 모으곤 합니다.
이번 프로젝트에서는 한국교통안전공단에서 제공한 2020년 자동차 결함 리콜 데이터를 활용하여 유의미한 패턴 및 인사이트를 발굴하고 시각화하는 실습을 진행하도록 하겠습니다.
프로젝트 목표
- 한국교통안전공단 자동차 결함 리콜 데이터를 분석하여 유의미한 정보 도출
- 탐색적 데이터 분석을 수행하기 위한 데이터 정제, 특성 엔지니어링, 시각화 방법 학습
프로젝트 목차
- 데이터 읽기: 자동차 리콜 데이터를 불러오고 Dataframe 구조를 확인
1.1. 데이터 불러오기 - 데이터 정제: 결측치 확인 및 기초적인 데이터 변형
2.1. 결측치 확인
2.2. 중복값 확인
2.3. 기초적인 데이터 변형 - 데이터 시각화: 각 변수 별로 추가적인 정제 또는 feature engineering 과정을 거치고 시각화를 통하여 데이터의 특성 파악
3.1. 제조사별 리콜 현황 출력
3.2. 모델별 리콜 현황 출력
3.3. 월별 리콜 현황 출력
3.4. 생산연도별 리콜 현황 출력
3.5. 4분기 제조사별 리콜 현황 출력
3.6. 하반기 생산연도별 리콜 현황 출력
3.7. 워드 클라우드를 이용한 리콜 사유 시각화
데이터 출처
1. 데이터 읽기
필요한 패키지 설치 및 import한 후 pandas를 사용하여 데이터를 읽고 어떠한 데이터가 저장되어 있는지 확인합니다.
#가장 기본적인 라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt #그래프, 데이터 시각화'
#seaborn 깔끔한 시각화를 위해 사용하는 라이브러리
!pip install seaborn==0.9.0 #라이브러리 버전을 맞춰주는 작업
import seaborn as sns
print(sns.__version__)
# missingno라는 라이브러리가 설치되어 있을 경우 import
try:
import missingno as msno
# missingno라는 라이브러리가 설치되어 있지 않을 경우 설치 후 import
except:
!pip install missingno
import missingno as msno
# pd.read_csv를 통하여 dataframe 형태로 읽어옵니다.
df = pd.read_csv("./data/한국교통안전공단_자동차결함 리콜현황_20201231.csv", encoding="euc-kr")
#인코딩 지정
# 상위 5개 데이터를 출력합니다.
df.head()
#출력결과

#데이터 확인
df.head(10)
df.tail() # 하위 5개 데이터 출력
df.info() #dataframe 정보를 요약하여 출력
2. 데이터 정제
데이터를 읽고 확인했다면 결측값(missing data), 중복값(duplicates)을 처리하고 열 이름 변경과 같은 기초적인 데이터 변형을 진행해봅시다.
2.1 결측치 확인
- missingno.matrix() 함수를 이요하여 결측치를 시각화 해보기
- isna() 함수 사용해보기
import matplotlib.font_manager as fm
#한국어를 시각화하기위해서는 우리말 폰트를 등록해서 지정해야됌
#폰트가 깨지지않도록
font_dirs = ['/usr/share/fonts/truetype/nanum', ]
font_files = fm.findSystemFonts(fontpaths=font_dirs)
for font_file in font_files:
fm.fontManager.addfont(font_file)
#기본적인 설정(폰트, rc -> 마이너스 기호 깨지는 것 방지하기 위해)
sns.set(font="NanumBarunGothic",
rc={"axes.unicode_minus":False})
msno.matrix(df) # df의 열별로 결측치를 시각화하여 보여줌
plt.show()
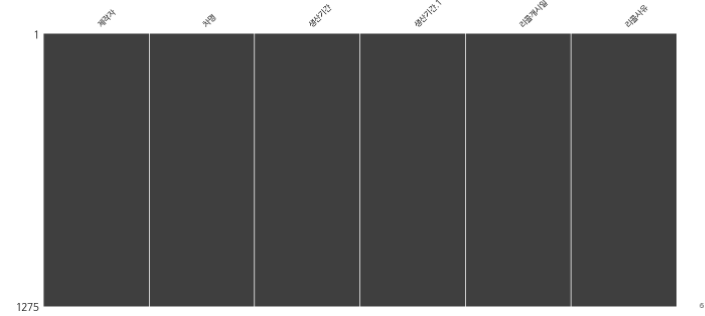
# 각 열 별로 결측치의 갯수를 반환합니다. (True:1, False:0)
df.isna().sum()
2.2. 중복값 확인
duplicated() 함수를 이용하여 중복값을 확인해봅시다.
#입력 오류, 저장 과정에서 잘못되어 중복값이 들어간 경우 확인해서 제거?
df[df.duplicated(keep = False)] #중복되어있는 것, argument는 중복되어있는 값을 출력할지말지?
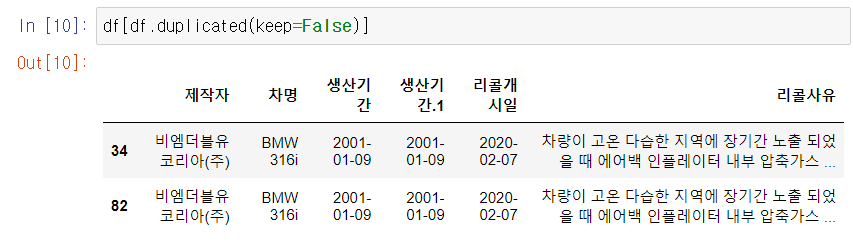
출력결과 결측치는 없었지만 중복값이 있는 것을 확인!!
drop_duplicates() 함수를 이용하여 중복값을 제거합니다.
df = df.drop_duplicates() # 중복값 제거 후 len 함수를 통해 길이로 제거되었는지 확인해볼수있음.
2.3 기초적인 데이터 변형
현재 생산기간, 생산기간.1, 리콜개시일 열은 모두 object 타입, 즉 문자열로 인식되고 있습니다.
분석을 위해 연도, 월, 일을 각각 정수형으로 저장합니다.
추가적으로 분석의 편리를 위해 열 이름을 영어로 바꿔줍니다.
#날짜 연도, 월 ,일로 나누기 (생산기간)
def parse_year(s):
return int(s[:4]) #날짜를 갖고와서 int 형으로 변환
def parse_month(s):
return int(s[5:7]) #인덱스 5,6
def parse_day(s):
return int(s[8:])
# Pandas DataFrame에서는 row별로 loop를 도는 것이 굉장히 느리기 때문에
#apply() 함수를 이용하여 벡터 연산을 진행합니다.
df['start_year'] = df['생산기간'].apply(parse_year)
df['start_month'] = df['생산기간'].apply(parse_month)
df['start_day'] = df['생산기간'].apply(parse_day)
df['end_year'] = df['생산기간.1'].apply(parse_year)
df['end_month'] = df['생산기간.1'].apply(parse_month)
df['end_day'] = df['생산기간.1'].apply(parse_day)
df['recall_year'] = df['리콜개시일'].apply(parse_year)
df['recall_month'] = df['리콜개시일'].apply(parse_month)
df['recall_day'] = df['리콜개시일'].apply(parse_day)
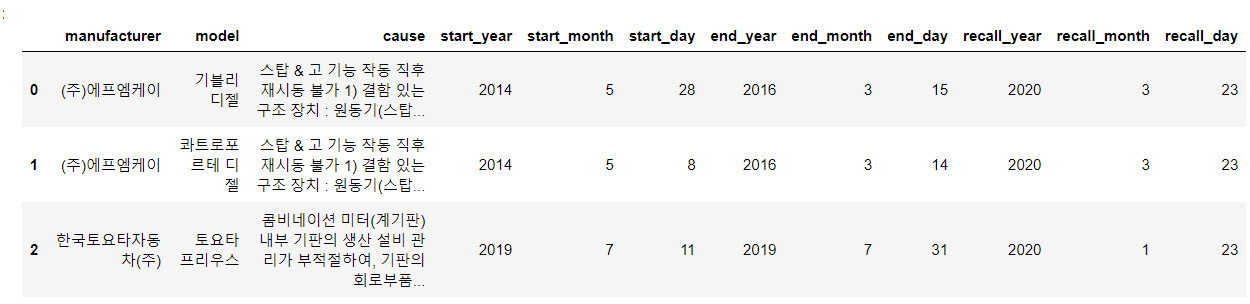
df.head(3)
# 불필요한 열은 버리고, 열 이름을 재정의합니다.
#이름을 재정의하는 이유는 우리말로 되어있는 것을 영어로 재정의하는, 개발자의 재량에 따라..
df = df.drop(columns=['생산기간', '생산기간.1', '리콜개시일']).rename(columns={'제작자': "manufacturer", "차명": "model", "리콜사유": "cause"})
df.head(3)
실행결과 : 열 이름이 모두 영어로 정의되고, 불필요한 컬럼들은 삭제 됌!
#데이터 프레임의 최소값과 최대값을 확인해보기
df.recall_year.min(), df.recall_year.max()
#출력결과 ( 2019,2020)
#2020년 데이터만 남기기
df = df[df['recall_year']== 2020]
len(df) # len 함수를 통해서 2019 데이터는 제외되었는지 확인해보기