- 프로젝트 개요
- 프로젝트 진행 순서
- 프로젝트 진행 과정(데이터 전처리/ 모델 구축)
- 결과 시각화 및 성능 개선
1. 프로젝트 개요
딥러닝 기술을 활용하여 영화 리뷰데이터로 영화의 평점을 예측해보기
그동안에 공부한 딥러닝과 자연어처리를 연관지어 할 수 있는 프로젝트를 계획해보았다.
2. 프로젝트 진행 순서
1) 데이터 수집
2) 데이터 전처리
3) 모델 구축
4) 결과 시각화 및 성능 테스트
팀원 총 6명이 각각 역할 분담을 해서 진행을 했고 나는 데이터 전처리와 모델 구축을 담당했다.
3. 프로젝트 진행 과정
1 )데이터 전처리
- 네이버 영화 리뷰 데이터를 크롤링을 통해 수집했고 총 10000개의 데이터를 엑셀파일로 받아서 읽어왔다.

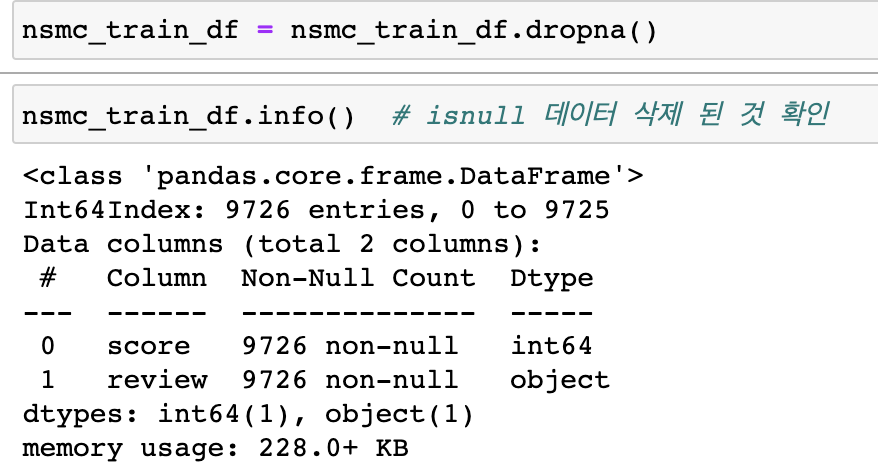
- null 데이터 삭제
- x_data, y_data 분리( 리뷰/ 평점)

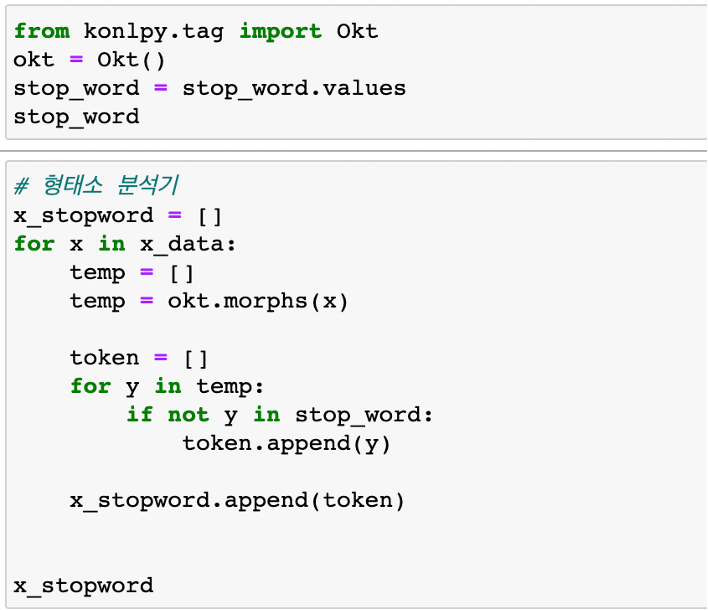
- 불용어 제거 / 품사 명사만 추출!
okt 형태소 분석기를 사용해서 불용어 제거
(불용어 제거는 안하고 진행을 했는데 모델 정확도가 너무 낮아서..혹시 몰라서 불용어 제거)
불용어 리스트는 구글링해서 txt 파일로 받아와서 사용을 했다.

- 단어 빈도수 체크해서 전체 리뷰 데이터에서 빈도수가 낮은 단어는 제외시킴


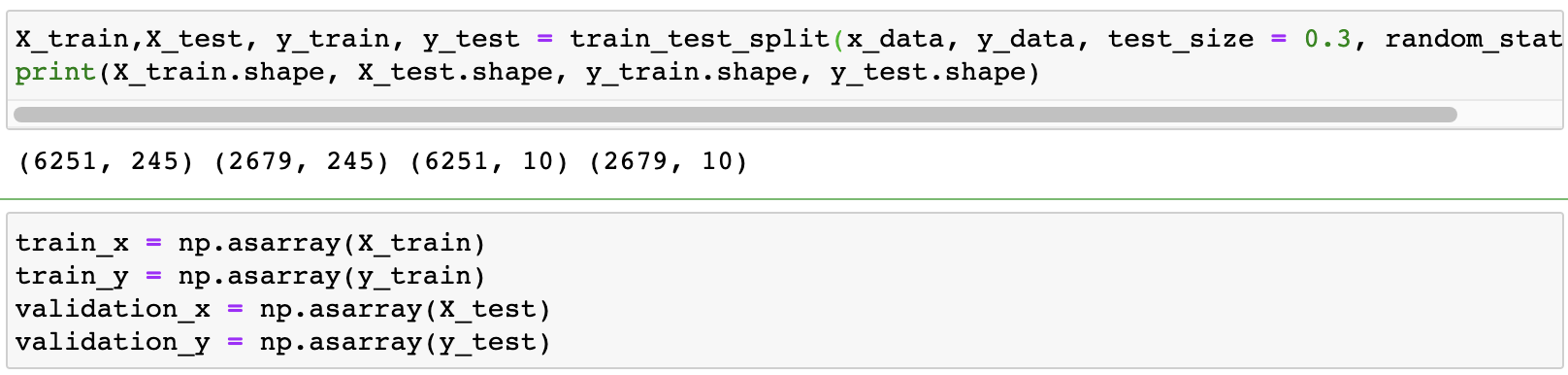
- 리뷰 데이터 단어 기반 인코딩
Tokenizer클래스를 이용해서
단어를 sequence로 변환, 길이를 맞춰주는 패딩 작업까지 진행을 해보았다.

평점 데이터는 원핫인코딩으로 진행을 했다.

마지막으로 모델 학습을 위해 데이터를 train, validation 데이터로 분리했다.
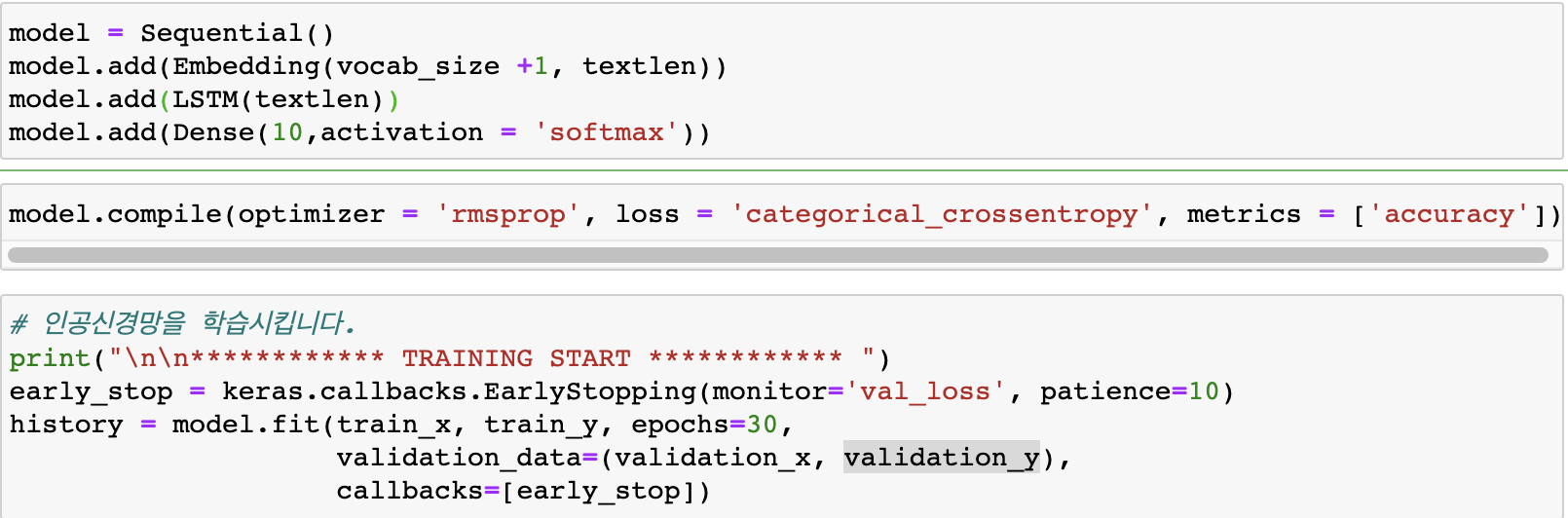
2. 모델 구축
LSTM 을 사용해서 테스트해보고 성능이 너무 안좋아서.. GRU 모델로도 테스트를 해보았음.
GRU로 학습시켰을 때 속도가 더 빨라서 최종 모델로 사용했다.
- LSTM
- GRU

3. 결과 및 성능 확인
정확도가 60%가 채 되지않는다..흡
감정분석을 해야되는건지 데이터 평점이 좀 치우쳐져 있는 것인지 아쉬운 결과가 나왔다..

4. 평점 예측 테스트
리뷰 데이터로 평점을 예측해보았다..^_^


'AI' 카테고리의 다른 글
| GAN(Generative Adversarial Network)에 대해서 알아보자 (0) | 2022.01.17 |
|---|---|
| [AI] Auto Encoder로 데이터를 복구하기? (0) | 2022.01.17 |
| RNN:: LSTM이란 무엇일까 (0) | 2022.01.12 |
| [자연어처리] KoNLPy를 이용한 형태소 분석, 품사 태깅 (0) | 2021.12.27 |
| [자연어 처리] 언어학에 대해서 배워보자 (0) | 2021.12.27 |


